Thank you!
I needed to collect a small pseudorealistic test-case dataset for my GMAT method and in order to do that I had put here a small and really stupid-looking survey (it looked like this). Now that I have my data collected (I didn't need much), I don't need any more input, but still thank you for stopping by.
In order not to leave your effort of stopping by unappreciated, I shall provide you with the dataset resulting from that survey. The dataset contains the "mood-based movie preferences" of some of our students (those that voluntarily responded to my call) and is certainly not something you'd use for a scientific study, but it is interesting enough to be usable in a small course project on data analysis or something like that. So, go on, and download the CSV here.
The dataset does seem to contain some simple verifiable patterns. For example, here's a decision tree for predicting the sex of a person, constructed from this dataset.
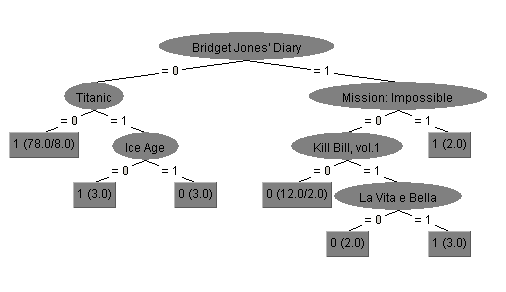
Having "Bridget Jones' Diary" and "Titanic" as the first attributes to consider seems pretty natural, doesn't it? :)
(BTW, the tree shown above was obtained using WEKA. Here's the dataset in the ARFF format, in case you'll be willing to use WEKA on it yourself).